什么是激活函数
在计算网络中,一个节点的激活函数定义了在给定了一个或一组输入时该节点的输出。在人工神经网络中,这样的函数也叫做传输函数。
激活函数的一些理想属性
- 非线性:当激活函数是非线性时,它可以看成泛函数逼近器 (universal function approximator)。恒等函数不满足这个性质,所以当多层网络使用这个激活函数时,整个网络相当于一个单层网络模型。
- 连续可微:在使用基于梯度的优化方法时,这个性质是必须的。
- 范围:当激活函数的输出是有限值时,基于梯度的优化方法更稳定,因为特征的表示受有限权值的影响更显著。当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的学习速率。
- 单调:当激活函数单调时,能够保证单层模型是凸的。
- 具有单调导数的平滑函数:在某些情况下具有更好的泛化性能。
- 在原点附近近似恒等函数:激活函数具有此性质时,如果权重在初始化时获得很小随机值,神经网络的训练将会非常高效。否则就要精心初始化权重。
常见激活函数
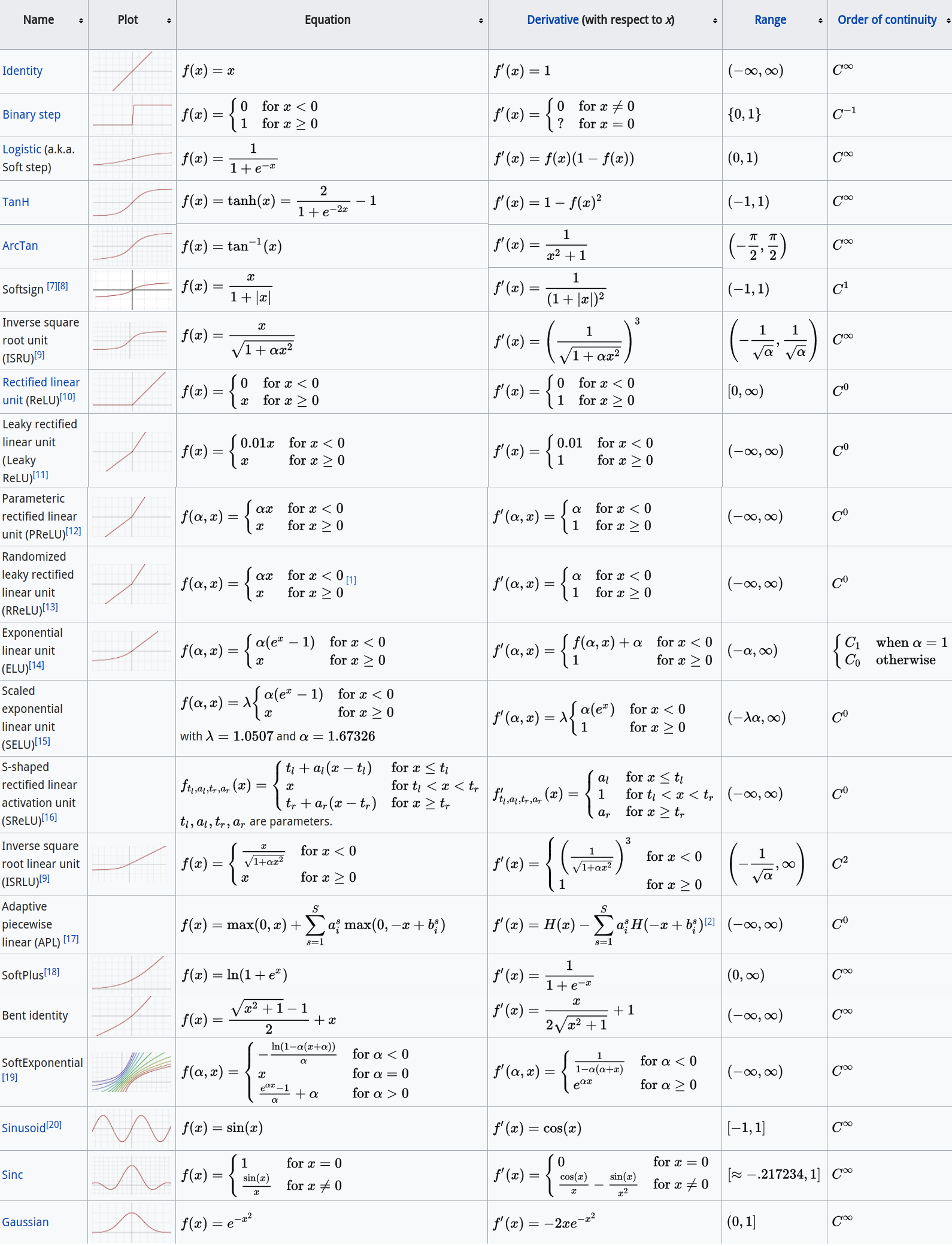
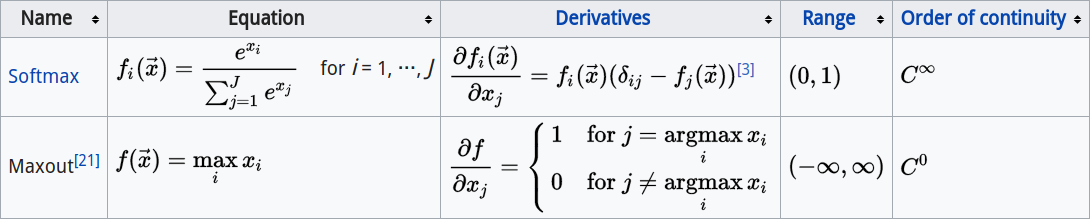
除此之外,Google 最近还提出了一个新的激活函数 swish。
一些激活函数的优劣
Sigmoid
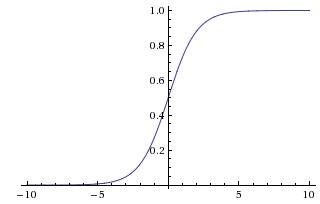
它的数学形式如下:$\sigma(x) = 1 / (1 + e^{-x})$
它取一个实数值,并且把它压缩到[0,1]
近几年使用 Sigmoid 的人越来少,主要因为它的两个缺点:
- Sigmoid 容易杀死梯度。当输入非常大或非常小的时候,它的梯度几乎为0,即发生梯度消失。在初始化权重时,如果权重太大,大多是神经元就会饱和,网络几乎不能学习。
- Sigmoid 的输出不是0均值的。如果进入神经元的数据总是正的,那么它的梯度也全是正的或负的。这可能会导致在梯度更新权重时出现我们不希望的锯齿状波动。
Tanh
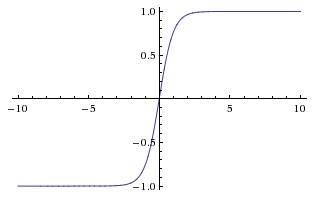
它将一个实数值压缩到[-1,1]。类似于 sigmoid 函数,它也容易饱和,但它的输出是0均值的。在实践中,它的非线性性好于 sigmoid 。
它的数学形式如下:$tanh(x) = 2\sigma(2x) - 1$
ReLu
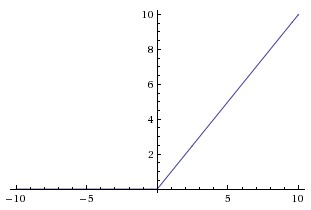
线性整流函数 (Rectified Linear Unit) 近几年变得越来越流行。
它的数学形式如下:$f(x) = max(0, x)$
ReLu 的优点:
- 他在随机梯度下降时,收敛速度比 sigmoid 快很多。
- 它只需要一个阈值就可以得到激活值,不需要大量运算。
ReLu 的缺点:虽然 ReLu 不会发生梯度消失,但是可能出现不可逆转的“死亡”。例如,当大梯度流经 ReLu 神经元导致权重更新后,神经元不会再次在任何数据点上激活。如果发生这种情况,那么流过该单元的梯度将从此点永远为零。
Maxout
它的数学形式如下:$f(x) = max(w_{1}^{T}x + b_{1}, w_{2}^{T}x + b_{2})$
实际上,ReLu 和 Leaky ReLu 都是它的特殊形式,所以它有 ReLu 的优点却没有 ReLu 的缺点。坏处是它使得参数翻倍,导致总参数量非常大。
Swish
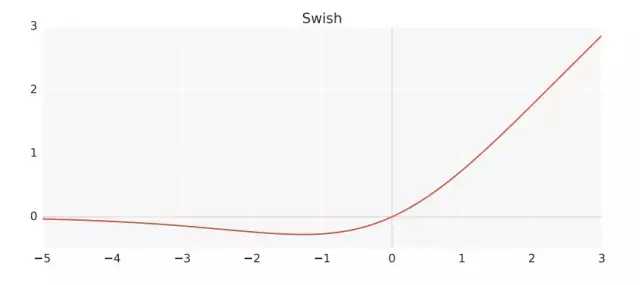
它的数学形式如下:$f(x) = x \cdot \sigma(\beta x)$,其中 $\beta$ 是一个常数。
Swish 具备无上界有下界、平滑、非单调的特性,这些都在 Swish 和类似激活函数的性能中发挥有利影响。虽然 swish 可能发生梯度缩减,但是在使用归一化的情况下,网络层数较深时,它的性能优于 ReLu。
Reference
[1] https://en.wikipedia.org/wiki/Activation_function
[2] http://cs231n.github.io/neural-networks-1/
[3] https://arxiv.org/abs/1710.05941