摘要
数据库索引也可以看做模型:B树把键映射到有序数组的某个位置,散列把键映射到无序数组的某个位置,Bitmap 把键映射到布尔值。那么这些索引技术能不用机器学习模型来做呢?本篇论文给出了一些启发性的尝试。
背景知识
一般索引可以分为三类:Range Index, Point Index, Existence Index.
他们通常分别用B树、散列、Bitmap实现。
Range Index
B树能找到某个数据所在的区间,即[pos, pos + pagesize],它在机器学习模型中表现为回归树:它把键映射到一个有最小和最大误差的位置,即[pos - min_err, pos + max_err]。因此我们可以用其他机器学习模型代替它。
用机器学习模型来代替B树之前,我们要先解决一些技术难题: B树对插入和查找有有限的成本,并且对缓存利用的特别好。
用神经网络的优势在于并行计算的快速,除此之外B树需要log n次操作而神经网络只要常数次。
从图上可以看出索引是CDF(又称分布函数)。我们可以对数据的分布函数进行建模以预测位置:$$ p = F(key) * N $$
其中p是我们预测的位置,N是键的总数。B树通过构建回归树来学习这个数据分布,那么机器学习模型也可以做。
RM-Index
受B树的启发,我们采用递归模型索引 (RM-Index)。
第l层的第k个模型,记作$ f_l^{(k)} $, 我们使用如下Loss训练模型:
$$ L_l = \sum_{(x,y)}(f_l^{(\lfloor M_l f_{l-1}(x) / N \rfloor)}(x) - y)^2 $$
$$ L_0 = \sum_{(x,y)}(f_0(x) - y)^2 $$
这个模型的好处有:它将空间划分为更小的子范围,使得在更少的操作下达到了“最后一公里”的准确率,此外它还可以将整个索引表示为TPU / GPU 的稀疏矩阵乘法。
Hybrid Indexes
递归模型的好处还有每个模型是独立的,因此我们可以用不同的模型来构建。本文采用两种模型:
- 0~2层FC,ReLu,每层最多32个神经元
- 当NN的max_abs_err大于阈值时使用B树

它的参数可以用网格搜索进行优化,本文发现对于B树典型的page-sizes,阈值设为128或256效果很好。
结果
为了对比learned index和B树,本文用了4个数据集。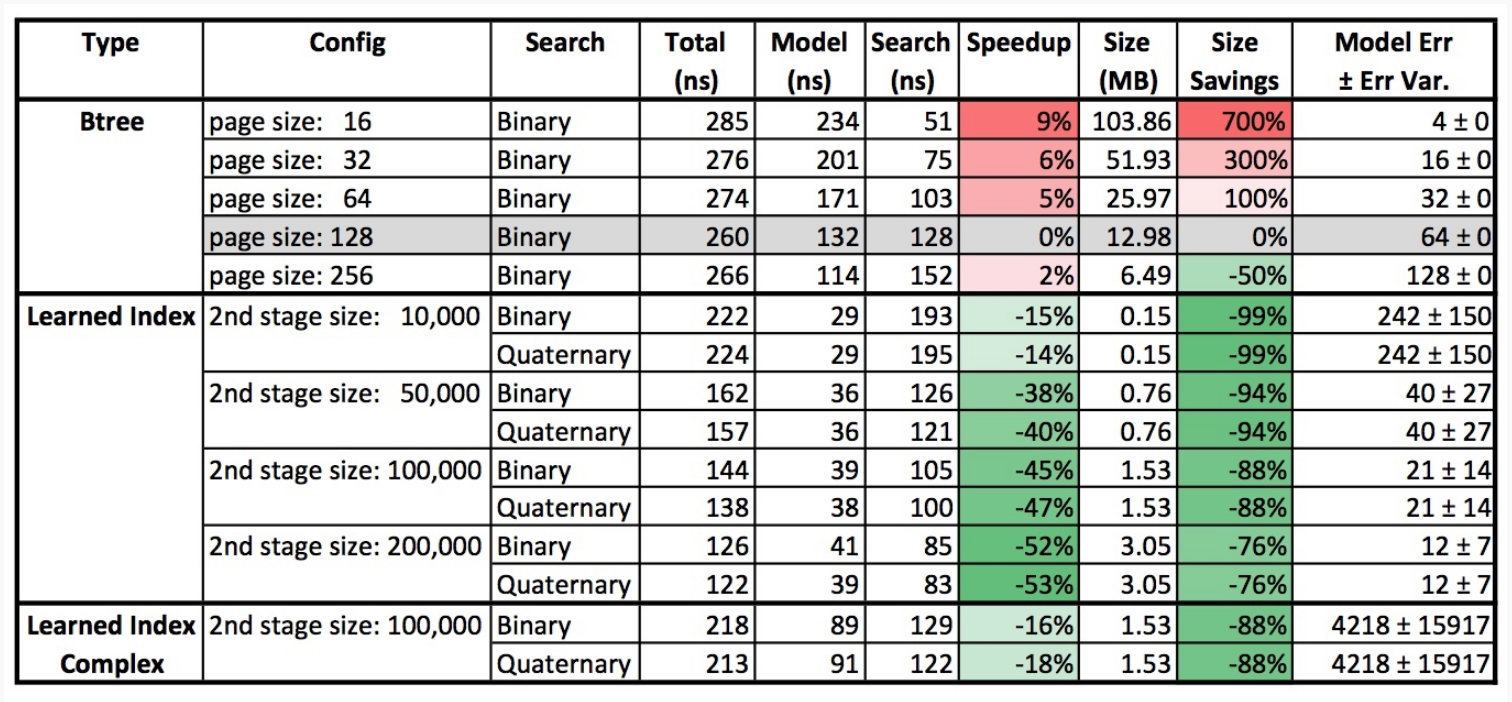
总的来说learned index比B树更快并且更省空间。然而它也面临着其他挑战,比如它增删改的代价比较大,对于NN模型,retrain的代价是无法预测的,并且为了达到last mile导致过拟合,模型的泛化性能堪忧,这直接导致对于新数据可能要retrain。
要降低retrain成本,一个有效的解决方案就是建立delta-index。另外我们可以用warm-start来加速训练,特别是对于依赖梯度下降优化的模型。